Aprendizado de máquina: abordagem geral para casos de negócios de cassino


Após uma carreira em SEO que durou duas décadas, Paul voltou sua atenção para os usos práticos da inteligência artificial, o que o levou a visitar regularmente a equipe de pesquisa de IA da universidade enquanto explorava novas maneiras de fazer sucesso como afiliado de um cassino.
No post anterior, vimos a motivação para explorar a I.A. Agora vamos dar uma olhada em alguns exemplos práticos de problemas do mundo real com os quais você pode estar familiarizado, examinaremos o tipo de problema e exploraremos abordagens para resolvê-los, bem como algumas armadilhas.
Como você deve se lembrar da última vez, apresentar a IA ao seu negócio não requer um cientista espacial.
A primeira etapa é identificar um caso de negócios.
Talvez você tenha uma tarefa repetitiva e demorada. Um bom teste para determinar se deve considerar a solução de um problema de aprendizado de máquina deve ser realizado.
Se pergunte:-
- Eu tenho um congestionamento no fluxo de trabalho?
- Tenho um processo de controle de qualidade que pode ser automatizado?
- Qual (is) tarefa (s) ou manual (is) representam o maior custo para a organização?
- Se eu aumentar a produção em 10x, quais rodas você espera que caiam primeiro?
(assumindo que alocar mais funcionários / recrutamento, etc., não é uma opção)
Alto fluxo de trabalho, economia de custos e desafios de dimensionamento são lugares óbvios para começar a analisar a implementação de algoritmos de aprendizado de máquina (ML).
No entanto, um uso esquecido da IA é a garantia de qualidade. Os humanos são muito subjetivos quando se trata de avaliação quantitativa. Somos inerentemente subjetivos e aplicamos nossos preconceitos e preferências individuais ao nosso julgamento.
Como você deve se lembrar de minha postagem anterior, esbocei três exemplos onde o aprendizado de máquina pode ser aplicado para resolver alguns problemas bastante triviais, como: –
- Classificação de texto – distingue automaticamente entre futebol (EUA) e futebol (Internacional).
- Medir a relevância entre o texto vinculado em um parágrafo e a página de destino.
- Escalonar a geração de conteúdo usando modelos de linguagem profunda
Tendo passado as últimas duas décadas trabalhando em SEO, é um bom lugar com alguns exemplos de aplicativos para aprendizado de máquina. Será um contexto familiar para leitores familiarizados com a implantação de SEO em grande escala, ao mesmo tempo em que apresenta conceitos para ajudá-lo a entender os fundamentos do ML, independentemente do know-how técnico ou estatístico. Mas é fora da função de aquisição e marketing que quero me concentrar neste post. Por enquanto, é o processo e a abordagem para lidar com os problemas de ML que eu queria ajudar a estabelecer em sua mente.
‘Por que’ em vez de ‘Como’
Manter o foco em “Por que”, em vez de “Como”, é possivelmente a lição mais valiosa que aprendi nos últimos seis anos enquanto explorava o aprendizado de máquina
Com o aprendizado de máquina e a IA em geral, é mais importante do que nunca manter o foco no problema, caso contrário, há uma tendência de se perder rapidamente por semanas ou até meses.
O campo é vasto e está crescendo tão rapidamente que, quando você piscar, haverá uma nova metodologia para resolver o problema com mais precisão. Da mesma forma, se você aborda o ML com o desejo de manter uma abordagem prática, é provável que se sinta oprimido pela matemática sem primeiro estabelecer uma razão sólida “Por que”.
Felizmente, o campo está bem estabelecido com bibliotecas de software altamente otimizadas e fáceis de usar disponíveis para implementação rápida. Portanto, não há necessidade de reinventar a roda. Por este motivo, é importante: –
- Entender o tipo de problema de ML
- Familiarize-se com os dados
- Foco nos objetivos de negócios
- Treinar, testar, medir, iterar
- Fracasse rápido / aprenda rápido
Exemplos de processos de negócios que são solucionados por máquina
- Previsão dos valores do jogador ao longo da vida
- Detecção de problemas com jogos de azar
- Recomendação de produto – jogadores que jogam ‘x’ também jogam ‘y’
- SEO Tecnico – soft 404 detecção.
- Processos de Offsite SEO – garantia de qualidade do link
Por enquanto, vamos examinar brevemente os desafios relacionados a ‘prever o valor do tempo de vida’ e desenvolver uma intuição mais profunda em torno da causa válida da detecção do ‘problema do jogo’.
Compreendendo o Problema de Aprendizado de Máquina
A chave para resolver qualquer problema é primeiro entender o problema. Portanto, é provavelmente um bom momento para introduzir mais alguns conceitos básicos.
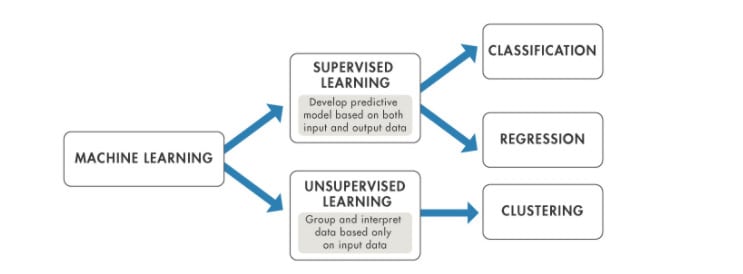
De modo geral, existem dois tipos principais de problemas na aprendizagem de máquinas: supervisionado e não supervisionado. Ambos os tipos ou problemas requerem dados de treinamento.
-
Problemas de aprendizado de máquina supervisionado. Nossos dados são rotulados. Então isso nos fornece conjuntos de exemplos. Nos primeiros algoritmos de detecção de spam de e-mail, esses seriam e-mails marcados como ‘spam’ e e-mails marcados como ‘ham’.
-
Problemas de aprendizado de máquina não supervisionados. Os nossos dados não estão etiquetados ou categorizados. Nesse caso, usamos algoritmos de aprendizado de máquina para ajudar a organizar os dados. Considere uma tabela de registros do usuário, podemos estar procurando algum tipo de semelhança ou mesmo dissimilaridade, ou comportamentos comuns. Em dados de série temporal, como análise da web, podemos estar procurando tendências ou mudanças nas tendências.
Há literalmente um número ilimitado de aplicativos para os dois tipos de aprendizado de máquina. Tudo depende da natureza dos seus dados e do sinal que você deseja extrair do ruído.
Witchcraft Fora do Alcance
Embora você provavelmente já tenha ouvido falar muito sobre aprendizado profundo e redes neurais, vamos ficar longe dessa abordagem por enquanto. Não se preocupe, chegaremos ao aprendizado profundo em postagens futuras. Embora as redes neurais profundas muitas vezes forneçam melhores resultados e aprendizado de máquina estatística, muitas vezes são difíceis de treinar, exigem conjuntos de dados significativamente maiores e os resultados não podem ser facilmente interpretados, transformando a inferência do modelo em uma caixa preta.
Caixas pretas não interpretáveis são ótimas se você for um monopólio de mecanismo de pesquisa em um caso antitruste de € 2,4 bilhões, mas não tão boas se você estiver depurando um classificador de ‘jogo problemático’. Para nosso propósito, nosso objetivo é resolver o problema rapidamente, estabelecer uma linha de base para precisão.
Eles literalmente funcionam como mágica, isso é tudo que precisamos saber por enquanto 😉
Famílias de algoritmos de aprendizado de máquina
Embora alguns desses algoritmos pareçam ser da Starship Enterprise, a maioria das bibliotecas de aprendizado de máquina são muito fáceis de usar, elas implementam treinamento e validação (teste) de modelo em duas ou três linhas de código. Ciência do foguete, não é.
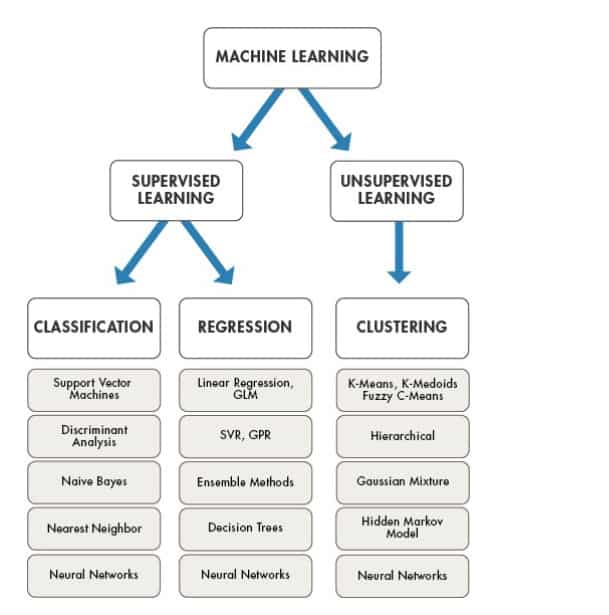 Image copyright: www.mathworks.com
Image copyright: www.mathworks.com As três famílias básicas de algoritmos são as seguintes: –
- Regressão: calcule a relação probabilística entre as variáveis para fins de previsão ou predição. Os problemas de regressão são aqueles em que tentamos fazer uma previsão em escala contínua. Algoritmos: Regressão Linear, Regressão Bayesiana, Regressão de Vetores de Suporte (SVR), Regressão Polinomial, Regressão de Ridge
-
Classificação: calcule a categoria (ou classe) de um item e a confiança (probabilidade) da classificação. Um problema de classificação é um problema em que usamos dados para prever em qual categoria algo se enquadra. Algoritmos: regressão logística, classificador Naive Bayes, máquinas de vetores de suporte (SVM), árvores de decisão, floresta aleatória
-
Clustering: agrupe os dados em classes diferentes, onde os dados de cada classe compartilham a semelhança. Um problema de agrupamento não é supervisionado, não temos rótulos nos dados, então estamos tentando usar os dados para inferir os rótulos com base em como os pontos de dados se enquadram em grupos, clusters ou classes. Algoritmos: K-médias, K-vizinhos mais próximos, deslocamento médio, cluster hierárquico, DBSCAN
Entendendo o Problema
Agora temos alguns conceitos básicos . Vamos examinar mais uma vez os problemas a seguir e entendê-los melhor em termos de problemas de aprendizado de máquina: –
Problema #1: Previsão dos valores do jogador vitalício (LTV)
Uma vez que estamos prevendo o valor do jogador, ou seja, um número em uma escala contínua (exemplo: € 2.330) em oposição a uma classe discreta (exemplo: cat / dog, spam / ham), então o problema deve geralmente ser considerado um “problema de regressão”, desde que tenhamos dados suficientes para derivar um modelo preciso. Caso os dados não estejam disponíveis para prever com precisão o LTV, uma abordagem alternativa seria pegar os dados históricos e repensar o problema como um problema de classificação, onde estamos prevendo classes, grandes ou não.
O pessoal de aquisição que está lendo este post já terá identificado o problema do ‘ovo e da galinha’, também conhecido pelos engenheiros do ML como o problema da “inicialização a frio” Ou seja, novos jogadores não têm um histórico de jogo. Isso nos leva a resolver um novo problema, o que podemos aprender com os dados de registro, se o jogador se conectou ao Facebook ou Twitter, o que podemos aprender com seu código postal, tipo de navegador, tipo de dispositivo, operadora de rede e análises avançadas de usuário do Google.
Nesse ponto, o problema se espalha em enriquecimento de dados, recuperação de informações, desambiguação de nomes de pessoas * e até mesmo um problema de inteligência de código aberto (OSINT) **.
* A desambiguação do nome da pessoa é tipicamente vista como um problema de agrupamento não supervisionado, onde o objetivo é particionar os contextos de um nome em diferentes clusters, cada um representando uma pessoa do mundo real. ( com uma conta do Facebook e um código postal, você consegue identificar com precisão o perfil do LinkedIn?)
** Inteligência de código aberto (OSINT) é uma metodologia multi-métodos (qualitativa, quantitativa) para coletar, analisar e tomar decisões sobre dados acessíveis em fontes publicamente disponíveis para serem usados em um contexto de inteligência. (Também conhecido como espionagem digital)
Por favor, não me julgue ainda! Vamos agora considerar o caso de negócios.
Nota: Eu não estava planejando cobrir OSINT e Desambiguação de Nomes de Pessoas nesta série, mas se você quiser que eu cubra esses tópicos no futuro, envie um tweet para @igamingsummit e diga a eles que é do seu interesse.
Motivação & Caso de Negócios
A medição mais fundamental do LTV seria um tudo-em-um ‘pega-tudo’ usando médias históricas baseadas em jogadores anteriores, idealmente segmentado por país.
Este ‘pega-tudo’ fornece: –
- a equipe de retenção: informações valiosas e um KPI sólido.
- a equipe de afiliados: munição de marketing.
No entanto, com alguma mineração / enriquecimento de dados e um pouco de inferência de modelo. Podemos ajudar na conversão e na reativação.
Ativação: – Uma vez que muitos cassinos online resolvem o problema de ativação pela força bruta, ou seja. usando centros de atendimento multilíngues dedicados, bem treinados e com equipe adequada. Considere o benefício comercial de ser capaz de direcionar os grandes jogadores potenciais para o recurso de call center de melhor desempenho. Operadores ainda menores e com menos recursos seriam capazes de priorizar recursos até mesmo limitados para ajudar o jogador na primeira etapa de depósito.
Retenção: – Da mesma forma, reter ou reativar jogadores é uma ciência e uma forma de arte. A capacidade de determinar com precisão a distribuição 80/20 em um banco de dados de jogadores perdidos, junto com estratégias de reativação ideais. Agora temos uma motivação poderosa para a equipe de retenção.
Lembre-se: o objetivo é identificar oportunidades para automatizar ou semi-automatizar e otimizar incrementalmente.
Agora que estamos começando a pensar sobre problemas específicos que, em termos de dados disponíveis, o caso de negócios e o tipo de saída, vejamos outro exemplo.
Problema #2: Detecção de problemas com jogo de azar
Já que venho de uma experiência em marketing digital (Pesquisa), é justo dizer que as questões regulatórias e éticas relacionadas ao iGaming são geralmente a última coisa em minha mente. No entanto, eu estava conversando com um amigo ontem, que me perguntou sobre aprendizado de máquina e detecção de ‘Jogo de azar’, chamando minha atenção para algumas das soluções de inteligência artificial que são atualmente pioneiras neste espaço.
É um problema interessante, embora nunca o tenha considerado antes. Achei que seria adequado incluir algumas reflexões sobre como abordaria esse desafio digno.
Eticamente, é um tópico importante, especialmente dada a situação atual do COVID e talvez colocar minhas ideias iniciais possa estimular a discussão e a exploração do problema e destacar alguns dos desafios que eu esperava de um modelo de aprendizado de máquina.
O que veio primeiro, o ovo ou a galinha?
No exemplo anterior, observamos o problema da “partida a frio”, também conhecido como o problema do “ovo e da galinha”. O problema de “inicialização a frio” geralmente se refere a problemas de agrupamento não supervisionados. Um exemplo é, Mecanismos de Recomendação (Filtragem Colaborativa).
Para inferir clusters de comportamento semelhante, primeiro exigimos algum comportamento do usuário a partir do qual possamos inferir similaridade de gosto, atribuindo o usuário a um determinado cluster. (Tradução em inglês, a Netflix não pode recomendar um filme até que você tenha assistido e avaliado pelo menos um filme. Quanto mais filmes você assistir e avaliar, melhores serão as recomendações.)
Do ponto de vista dos dados, existem dois tipos de jogadores problemáticos.
1. um jogador recreativo que desenvolve um problema ao longo do tempo enquanto joga no seu cassino.
2. um novo jogador que acabou de se registrar e já tem um problema de jogo.
Observe que temos desafios comerciais e éticos.
No caso do jogador que desenvolve o problema ao longo do tempo …
Há algum evento na linha do tempo nos dados que desencadeou o problema de jogo (como um prêmio de jackpot)? Nesse caso, em que ponto a empresa ficaria feliz em bloquear a conta, enquanto o jogador está perdendo os ganhos para a casa? Existe um meio feliz? Como avaliamos as prioridades de negócios?
O algoritmo não deve desencadear falsos positivos, uma vez que os jogadores problemáticos parecem quase exatamente os grandes apostadores e não há prêmios para bloquear a conta de um novo apostador.
Antes de prosseguirmos, agora é um momento tão bom quanto qualquer outro para considerar como medimos a precisão em sistemas de aprendizado de máquina.
Precisão de previsão, precisão vs recall
Como podemos ver em nosso exemplo de ‘problema de jogo’ a precisão é crucial, falsos positivos são totalmente inaceitáveis. Assim, quando medimos a precisão no aprendizado de máquina, medimos a precisão e o recall.
As origens da precisão e da recuperação como medida da exatidão vêm do campo da recuperação de informações e dos mecanismos de pesquisa como um meio de avaliar a qualidade de um conjunto de documentos recuperados ou resultados de pesquisa.
A precisão é a proporção de resultados relevantes na lista de todos os resultados de pesquisa retornados. O recall é a proporção entre os resultados relevantes retornados pelo mecanismo de pesquisa e o número total de resultados relevantes que poderiam ter sido retornados.
Recall = True Positives / True Positives + False Negatives
Note: A model that produces no false negatives has a recall of 1.0.
Precision = True Positives / True Positives + False Positives
Note: A model that produces no false positives has a precision of 1.0.
F1 Score = 2 * (Recall * Precision / Recall + Precision)
(AKA the Harmonic Mean)
Para mais informações sobre precisão e recall visite Google’s Machine Learning Crash Course
Eu prometo não mais matemática neste post.
Recapitule o que aprendemos
- Entendemos porque a precisão é crucial. Os falsos positivos são inaceitáveis.
- Identificamos dois tipos distintos de “jogador problemático” do ponto de vista dos dados. 1) novos jogadores depositantes que têm um problema de jogo preexistente. 2) jogadores existentes que desenvolveram um problema de jogo durante sua vida de jogador.
- Ambos os tipos são problemas distintamente diferentes que requerem abordagens diferentes
- Entendemos que o problema de “inicialização a frio” se aplica a algoritmos de agrupamento não supervisionados.
Com isso em mente, vamos continuar a explorar o “problema do jogo” um pouco mais fundo.
Como estamos abordando o problema usando o aprendizado de máquina estatístico em oposição ao aprendizado profundo, o conhecimento específico do domínio é importante. Como mencionei, o aprendizado profundo funciona por mágica, explicarei o porquê em um post posterior, mas por enquanto, apenas confie em mim.
Conforme você aborda um problema de aprendizado de máquina estatístico, o conhecimento do domínio é vital. Uma compreensão do domínio do problema nos fornece a intuição de quais dados são importantes para o (s) nosso (s) modelo (s) e, uma vez que não tenho experiência neste lado do negócio.
Chamei minha amiga para nos dar alguns conselhos, Yara, da Pearl Trust, é especialista em licenças de jogos em Curaçao, tendo primeiro me alertado sobre o “problema do jogo” e a necessidade do negócio de uma abordagem de IA. Eu descobri quem melhor para perguntar do que Yara para informações adicionais: –
Vejamos algumas dicas adicionais que ela gentilmente forneceu.
- Atualmente, os “jogadores problemáticos” estão principalmente sob a responsabilidade de atendimento ao cliente, oficial de CSR (responsabilidade social corporativa) ou oficial de jogo responsável designado com assistência do I.T fornecer dados específicos às partes interessadas.
- Atualmente o processo é amplamente manual com auxílio da TI. No entanto, existem algumas empresas agora desenvolvendo soluções automatizadas para esse problema.
A indicação comum de ‘problema de jogo’ inclui: –
- Perseguir perdas
- Tempos de jogo erráticos
- Sessão prolongada
O processo atual:-
- Jogadores potenciais adicionados à lista de observação
- Se o problema persistir e / ou piorar, a auto exclusão é recomendada
- Se a recomendação de auto exclusão for ignorada, o bloqueio da conta será feito como último recurso
Portanto, agora que entendemos melhor o processo interno para lidar com o “problema do jogo”, temos objetivos de negócios nos quais podemos nos concentrar.
Objetivos dos problemas com jogos de azar
Objetivo #1:automatizar a geração da lista de observação a ser distribuída às partes interessadas.
Objetivo #2: gerar dados de resumo suplementares para incluir em um relatório.
Continuaremos explorando esse problema fascinante em mais detalhes no próximo post. Exploraremos alguns dos algoritmos e suas características em relação aos dados com os quais normalmente trabalharíamos. À medida que exploramos esses e outros problemas, começaremos a desenvolver intuição em torno dos tipos de problemas distintamente diferentes.
Se você tiver pensamentos, considerações, perguntas ou tópicos específicos que gostaria que eu respondesse / cobrisse em postagens futuras, tweet @igamingsummit.
Sobre a Exposição Virtual SiGMA Europa:
O Grupo SiGMA tem o prazer de anunciar o lançamento de seu evento de novembro: a Exposição Virtual SiGMA Europa. O evento online, que decorre de 24 à 25, terá como foco o jogo europeu e o mercado de tecnologia.
Para mais informações sobre como patrocinar este evento entre em contato com Hamza e para explorar oportunidades de palestras entre em contato com Jeremy. Para se inscrever no evento, clique aqui.














