Машинное обучение: общий подход к бизнес-кейсам казино


В предыдущем посте мы рассмотрели мотивацию изучения ИИ. Теперь давайте рассмотрим несколько практических примеров реальных проблем, с которыми вы, возможно, знакомы, мы рассмотрим тип проблем и изучим подходы к их решению, а также некоторые общие подводные камни.
Как вы, возможно, помните из прошлого раза, для внедрения ИИ в ваш бизнес не требуется ученого-ракетчика.
Первый шаг – определить бизнес-кейс.
Возможно, у вас есть повторяющаяся и отнимающая много времени задача. Хороший тест на запах, чтобы определить, стоит ли рассматривать решение проблемы с помощью машинного обучения.
Спросите себя:
- Есть ли у меня узкое место в рабочем процессе?
- Есть ли у меня процесс контроля качества, который можно автоматизировать?
- Какие задачи с ручным управлением несут наибольшие затраты для организации?
- Если я увеличу производительность в 10 раз, какие колеса отвалятся первыми?
(при условии, что выделение большего количества персонала / набора и т. д. не вариант)
Узкие места, экономия средств и проблемы масштабирования – очевидные причины, с которых следует начать изучение алгоритмов машинного обучения (ML).
Однако одним из упускаемых из виду применением ИИ является обеспечение качества. HumanD очень субъективны, когда дело касается количественной оценки. Мы по своей природе субъективны и полагаемся на наши личные предубеждения и предпочтения.
Как вы, возможно, помните из моего предыдущего поста я привел три примера, где машинное обучение может применяться для решения некоторых довольно тривиальных проблем, таких как:
- Классификация текста – автоматическое различие между футболом (США) и футболом (международным).
- Измерение релевантности связанного текста в абзаце и целевой страницы.
- Масштабирование генерации контента с использованием моделей глубинного языка
Проведя последние два десятилетия, работая над SEO, здесь можно найти несколько примеров приложений для машинного обучения. Это будет знакомый контекст для читателей, знакомых с масштабным развертыванием SEO, а также с ознакомлением с концепциями, которые помогут вам понять основы ML, независимо от технических или статистических ноу-хау. Но в этом посте я хочу сосредоточиться не на функциях приобретения и маркетинга. На данный момент это процесс и подход к решению проблем машинного обучения, которые я хотел вам представить.
“Почему”, а не “Как”
Сосредоточение внимания на «почему», а не на «как», возможно, самый ценный урок, который я усвоил за последние шесть лет, изучая машинное обучение.
С машинным обучением и искусственным интеллектом в целом как никогда важно сосредоточиться на проблеме, в противном случае есть тенденция быстро уходить в исследовательские кроличьи норы на недели или даже месяцы.
Эта область обширна и растет так быстро, что к тому времени, как вы вернетесь, чтобы вздохнуть, появится новая методология, позволяющая более точно решить проблему. Точно так же, если вы подходите к машинному обучению с желанием придерживаться практического подхода, вы, скорее всего, будете поражены математикой, не установив сначала твердую причину «почему».
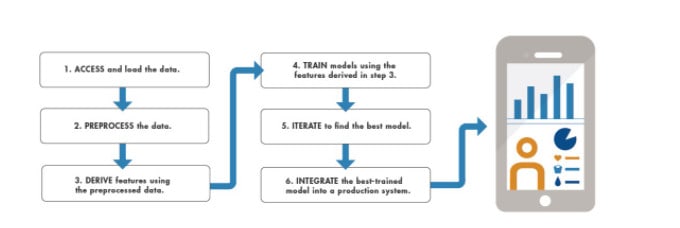
К счастью, эта область хорошо зарекомендовала себя с простыми в использовании, высоко оптимизированными библиотеками программного обеспечения, доступными для быстрого внедрения. Так что не нужно изобретать велосипед. По этой причине важно: –
- Понять тип проблемы машинного обучения
- Ознакомиться с данными
- Сосредоточиться на бизнес-целях
- Тренировать, тестировать, измерять, повторять
- Быстро терпеть неудачу / быстро учиться
Примеры машинно-решаемых бизнес-процессов
- Прогнозирование ценностей игрока на протяжении всей жизни
- Обнаружение проблем с азартными играми
- Рекомендация продукта – игроки, которые играют в ‘x’, также играют в ‘y’
- Техническое SEO – мягкое обнаружение 404.
- Внешние SEO-процессы – гарантия качества ссылок
А пока мы собираемся кратко рассмотреть проблемы, связанные с «прогнозированием жизненной ценности», и развить некоторую более глубокую интуицию в отношении достойной причины обнаружения «игровой зависимости».
Понимание проблемы машинного обучения
Ключ к решению любой проблемы – это сначала понять проблему. Так что, наверное, самое время познакомить вас с еще некоторыми фундаментальными концепциями.
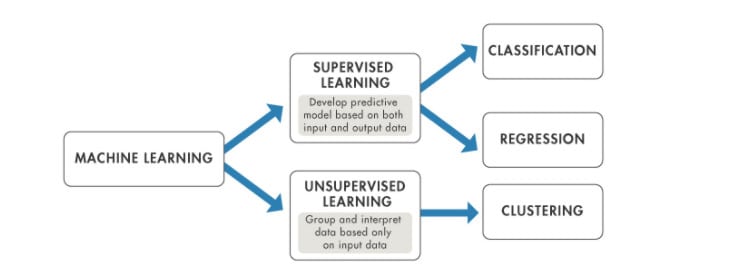
Вообще говоря, в машинном обучении есть два основных типа проблем: контролируемые и неконтролируемые. Оба типа или проблемы требуют обучающих данных.
- Задачи машинного обучения с учителем. Наши данные помечены. Чтобы предоставить нам набор примеров. В алгоритмах раннего обнаружения спама в электронной почте это будут электронные письма с пометкой «спам» и электронные письма с пометкой «плохая игра».
- Проблемы с машинным обучением без учителя. Наши данные не помечены или не разделены на категории. В этом случае мы используем алгоритмы машинного обучения, чтобы упорядочить данные. Рассмотрим таблицу пользовательских записей, возможно, мы ищем какое-то сходство или даже несходство или общее поведение. В данных временных рядов, таких как веб-аналитика, мы можем искать тенденции или изменения в тенденциях.
Для обоих типов машинного обучения существует буквально неограниченное количество приложений. Все зависит от характера ваших данных и сигнала, который вы хотите извлечь из шума.
Колдовство выходит за рамки
Хотя вы, вероятно, много слышали о глубоком обучении и нейронных сетях, мы пока не собираемся использовать этот подход. Не волнуйтесь, мы поговорим о глубоком обучении в следующих статьях. Хотя глубокие нейронные сети часто обеспечивают лучшие результаты и статистическое машинное обучение, их часто сложно обучить, они требуют значительно больших наборов данных, а результаты нелегко интерпретировать, что превращает вывод модели в черный ящик.
Непонятные черные ящики хороши, если вы являетесь монополистом поисковой системы в антимонопольном деле стоимостью 2,4 миллиарда евро, находящемся под пристальным вниманием, но не очень хороши, если вы отлаживаете классификатор “проблемной игры”. Для нашей цели мы стремимся быстро решить проблему, установить базовый уровень точности.
Они буквально работают по волшебству, это все, что нам сейчас нужно знать. 😉
Семейства алгоритмов машинного обучения
Хотя некоторые из этих алгоритмов звучат так, как будто они взяты из Starship Enterprise, большинство библиотек машинного обучения очень просты в использовании, они реализуют обучение и проверку (тестирование) моделей в двух или трех строках кода. Ракетостроение, это не так.
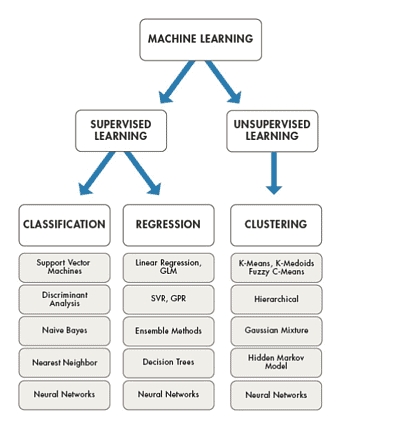 Авторские права на изображение: www.mathworks.com
Авторские права на изображение: www.mathworks.com Три основных семейства алгоритмов следующие:
- Регрессия: вычислить вероятностную связь между переменными для целей прогнозирования или предвидения. Проблемы регрессии – это проблемы, в которых мы пытаемся сделать прогноз в непрерывном масштабе. Алгоритмы: Linear Regression, Bayesian Regression, Support Vector Regression (SVR), Polynomial Regression, Ridge Regression
- Классификация: вычислить категорию (или класс) предмета и достоверность (вероятность) классификации. Проблема классификации – это проблема, когда мы используем данные, чтобы предсказать, в какую категорию что-то попадает. Алгоритмы: Logistic Regression, Naive Bayes Classifier, Support Vector Machines (SVM), Decision Trees, Random Forest
- Кластеризация: группируйте данные в разные классы, где данные в каждом классе имеют сходство. Проблема кластеризации является неконтролируемой, у нас нет меток в данных, поэтому мы пытаемся использовать данные для вывода меток на основе того, как точки данных попадают в группы, кластеры или классы. Алгоритмы: K-Means, K-Nearest Neighbours, Mean-shift, Hierarchical clustering, DBSCAN
Разбирая проблему
Теперь у нас есть несколько базовых концепций. Давайте еще раз взглянем на следующие проблемы и лучше поймем их с точки зрения задач машинного обучения:
Проблема #1: Прогнозирование ценности игрока на протяжении всей жизни (LTV)
Поскольку мы прогнозируем ценность игрока, т.е. число в непрерывной шкале (пример: 2330 евро) в отличие от дискретного класса (пример: кошка / собака), тогда проблема обычно должна рассматриваться как «проблема регрессии», если у нас есть достаточно данных, из которых можно получить точную модель. Если данные не доступны для точного прогнозирования LTV, альтернативным подходом будет использование исторических данных и переосмысление проблемы как проблемы классификации, когда мы прогнозируем классы, будь то высокие ставки или нет.
Люди, занимающиеся приобретением, читающие этот пост, уже заметили проблему «курицы и яйца», также известную инженерам машинного обучения как проблема «холодного старта». А именно у новых игроков нет игровой истории. Это приводит нас к решению новой проблемы: что мы можем узнать из регистрационных данных, подключился ли игрок к facebook или twitter, что мы можем узнать из его почтового индекса, типа браузера, типа устройства, оператора сети и расширенной пользовательской аналитики Google.
На этом этапе проблема переходит в обогащение данных, поиск информации, устранение неоднозначности имени человека * и даже проблему разведки с открытым исходным кодом (OSINT) **.
*Устранение неоднозначности имени человека обычно рассматривается как проблема неконтролируемой кластеризации, цель которой состоит в том, чтобы разделить контексты имени на различные кластеры, каждый из которых представляет людей из реального мира. (Говоря простым языком… учитывая учетную запись facebook и почтовый индекс, можете ли вы точно определить их профиль в LinkedIn?)
**Разведка с открытым исходным кодом (OSINT) – это методология с несколькими методами (качественная, количественная) для сбора, анализа и принятия решений в отношении данных, доступных в общедоступных источниках, для использования в контексте разведки. (AKA цифровой шпионаж)
Пожалуйста, не осуждайте меня! Давайте теперь рассмотрим бизнес-пример.
Примечание. Я не планировал освещать OSINT и устранение неоднозначности имен в этой серии, но если вы хотите, чтобы я освещал эти темы в будущем, напишите в Твиттере @igamingsummit и дайте мне знать, что это вам интересно.
Мотивация и бизнес-кейс
Самым фундаментальным измерением LTV было бы комплексное “всеобъемлющее” использование исторических средних значений, основанных на прошлых игроках, в идеале с разбивкой по странам.
Этот комплексный подход обеспечивает: –
- команда удержания: ценная информация и надежный KPI.
- аффилированная команда: маркетинговые амуниции.
Однако с некоторым анализом данных / обогащением и небольшим выводом модели. Мы можем помочь как с конверсией, так и с реактивацией.
Активация: – Так как многие онлайн-казино решают проблему активации перебором, т.е. использование специализированных, хорошо обученных, хорошо укомплектованных многоязычных центров обработки вызовов. Рассмотрите выгоду для бизнеса от возможности направлять потенциальных крупных игроков в наиболее эффективный ресурс колл-центра. Даже более мелкие, менее обеспеченные ресурсами операторы смогут определить приоритеты даже ограниченных ресурсов, чтобы помочь игроку на первом этапе депозита.
Удержание: – Точно так же удержание или повторная активация игроков – это одновременно наука и искусство. Возможность точно определить распределение 80/20 по базе данных проигравших игроков, а также оптимальные стратегии реактивации. Теперь у нас есть мощная мотивация для команды удержания.
Помните: цель – выявить возможности автоматизации или полу-автоматизации, а затем постепенной оптимизации.
Теперь, когда мы начинаем думать о конкретных проблемах, таких как точки зрения имеющихся данных, экономическое обоснование и тип вывода, давайте рассмотрим другой пример.
Проблема #2: Обнаружение проблем с азартными играми
Поскольку у меня опыт работы в области цифрового маркетинга (поисковой сети), будет справедливо сказать, что нормативные и этические вопросы, связанные с iGaming, как правило, в последнюю очередь меня волнуют. Однако только вчера я разговаривал с другом, который спросил меня о машинном обучении и обнаружении “проблем с азартными играми”, обратив мое внимание на некоторые решения искусственного интеллекта, которые в настоящее время являются пионерами в этой области.
Это интересная проблема, хотя раньше я никогда не рассматривал ее. Я подумал, что было бы уместно включить некоторые мысли о том, как я подойду к этой достойной задаче.
С этической точки зрения, это важная тема, особенно с учетом текущей ситуации с COVID, и, возможно, изложение моих первоначальных мыслей может подтолкнуть к обсуждению и дальнейшему исследованию проблемы и выявить некоторые из проблем, которые я мог бы ожидать от модели машинного обучения.
Что было первым, курица или яйцо?
В предыдущем примере мы отметили проблему «холодного старта», также известную как проблема «курица и яйцо». Проблема «холодного запуска» обычно связана с неконтролируемыми проблемами кластеризации. Один из примеров – механизмы рекомендаций (совместная фильтрация).
Чтобы сделать вывод о кластерах схожего поведения, нам сначала требуется какое-то поведение пользователя, из которого можно сделать вывод о сходстве во вкусе, отнеся пользователя к данному кластеру. (В переводе на английский язык Netflix не может рекомендовать фильм, пока вы не посмотрите и не оцените хотя бы один фильм. Чем больше фильмов вы посмотрите и оцените, тем точнее будут рекомендации.)
С точки зрения данных существует два типа проблемных игроков.
1. Игрок-любитель, у которого со временем возникает проблема во время игры в вашем казино.
2. Новый игрок, который только что зарегистрировался и уже имеет проблемы с азартными играми.
Обратите внимание, что у нас есть как деловые, так и этические проблемы.
В случае игрока, у которого проблема развивается со временем…
Есть ли событие на временной шкале в данных, которое вызвало проблему с азартными играми (например, выигрыш джекпота)? В таком случае, в какой момент бизнес будет счастлив заблокировать учетную запись, в то время как игрок теряет выигрыш? Есть золотая середина? Как мы взвешиваем приоритеты бизнеса?
Алгоритм не должен вызывать ложные срабатывания, поскольку проблемные игроки выглядят почти так же, как хайроллеры, и нет призов за блокировку счета нового хайроллера.
Прежде чем мы пойдем дальше, сейчас самое время подумать о том, как мы измеряем точность в системах машинного обучения.
Прогнозы, точность и отзыв
Как мы видим из нашего примера “проблема с азартными играми”, точность имеет решающее значение, ложные срабатывания совершенно недопустимы. Таким образом, когда мы измеряем точность машинного обучения, мы измеряем как точность, так и отзывчивость.
Истоки точности и отзыва как меры точности происходят из области поиска информации и поисковых систем как средства оценки качества набора извлеченных документов или результатов поиска.
Точность – это доля релевантных результатов в списке всех возвращенных результатов поиска. Отзыв – это отношение релевантных результатов, возвращенных поисковой системой, к общему количеству релевантных результатов, которые могли быть возвращены.
Отзыв=Истинные положительные стороны /Истинные положительные стороны + Ложноотрицательные
Примечание. Модель, которая не дает ложноотрицательных результатов, имеет отзыв 1,0.
Точность=Истинные положительные стороны /Истинные положительные стороны + Ложноположительные
Примечание. Модель, которая не дает ложноположительных результатов, имеет отзыв 1,0.
Оценка F1 = 2 * (отзыв * точность / отзыв + точность)
(AKA среднее гармоническое)
Для получения дополнительной информации о точности и отзывах посетите ускоренный курс Google по машинному обучению.
Я обещаю, что в этом посте больше не будет математики.
Кратко о том, что мы узнали
- Мы понимаем, почему точность так важна. Ложные срабатывания недопустимы.
- С точки зрения данных мы выделили два разных типа «проблемных игроков». 1) новые игроки, вносящие депозит, у которых уже есть проблема с азартными играми. 2) существующие игроки, у которых в течение жизни игрока возникла проблема с азартными играми.
- Оба типа – это совершенно разные проблемы, требующие разных подходов.
Мы понимаем, что проблема «холодного старта» применима к неконтролируемым алгоритмам кластеризации.
Имея это в виду, давайте продолжим немного глубже исследовать “проблемы с азартными играми”.
Поскольку мы подходим к проблеме, используя статистическое машинное обучение, а не глубокое обучение, важны знания в конкретной предметной области. Поскольку я уже упоминал, что глубокое обучение работает по волшебству, я объясню почему в более позднем посте, а пока просто поверьте мне.
Когда вы подходите к проблеме статистического машинного обучения, знание предметной области становится жизненно важным. Понимание предметной области дает нам интуитивное представление о том, какие данные важны для нашей модели (моделей), поскольку у меня нет опыта в этой части бизнеса.
Я обратился за советом к своему другу, Yara из Pearl Trust,который специализируется на Игровых лицензиях Кюрасао, впервые ознакомив меня с проблемой «азартных игр» и потребностями бизнеса в подходе к ИИ. Я подумал, у кого лучше спросить, как ни у Yara, для дополнительной информации: –
Давайте посмотрим на некоторые дополнительные сведения, которые она любезно предоставила.
- В настоящее время «проблемные игроки» в основном подпадают под сферу компетенции службы поддержки клиентов, сотрудника по корпоративной социальной ответственности (CSR) или назначенного ответственного сотрудника по азартным играм при содействии IT, для предоставления конкретных данных заинтересованным сторонам.
- В настоящее время этот процесс широко выполняется вручную с помощью IT. Однако сейчас несколько компаний разрабатывают автоматизированные решения этой проблемы.
Общие признаки «пристрастия к игре» включают: –
- Погоня за потерями
- Неустойчивое время игры
- Увеличенная продолжительность сеанса
Текущий процесс: –
- Потенциальные игроки добавлены в список наблюдения
- Если проблема сохраняется и / или ухудшается, рекомендуется само-исключение.
- Если рекомендация по само-исключению игнорируется, в качестве последнего средства применяется блокировка учетной записи.
Итак, теперь, когда мы лучше понимаем внутренний процесс решения «проблемной игры», у нас есть бизнес-цели, на которых мы можем сосредоточиться.
Цели пристрастия к игре
Задача #1: автоматизировать создание списка наблюдения для распространения среди заинтересованных сторон.
Задача #2: генерировать дополнительные сводные данные для включения в отчет.
Мы продолжим исследовать эту увлекательную проблему более подробно в следующем посте. Мы рассмотрим некоторые алгоритмы и их характеристики применительно к данным, с которыми мы обычно работаем. По мере того, как мы исследуем эти и другие проблемы, мы начнем развивать интуицию в отношении совершенно разных типов проблем.
Если у вас есть какие-либо конкретные мысли, соображения, вопросы или темы, на которые вы хотите, чтобы я отвечал / освещал в будущих публикациях, напишите в Твиттере @igamingsummit.
О выставке SiGMA Europe Virtual Expo:
SiGMA Group рада сообщить о запуске нового ивента в Ноябре – SiGMA Europe Virtual Expo. Онлайн-мероприятие, которое пройдет с 24 по 25 число, будет посвящено европейскому рынку игр и технологий.
За более детальной информации о спонсировании этого ивента, пожалуйста обратитесь к Hamza , a чтобы изучить возможности выступления, свяжитесь с Jeremy. Зарегистрироваться на выставку можно здесь.










