Aprendizaje automático: Enfoque general para los casos de negocios de casinos
Por Paul Reilly, ingeniero de IA, fundador de flashbitch.com, un sitio web de bonos de casino generado en gran parte por IA, un entusiasta de la tecnología y conferencista.
Después de una carrera de SEO que duró dos décadas, Paul se centró en los usos prácticos de la inteligencia artificial, lo que le llevó a formar parte del equipo de investigación de la universidad de la IA, mientras exploraba nuevas formas de darse a conocer como afiliado de casinos.
En el post anterior vimos la motivación para explorar la I.A.. Ahora vamos a ver algunos ejemplos prácticos de problemas del mundo real con los que puede estar familiarizado, examinaremos el tipo de problema y exploraremos enfoques para resolverlos, así como algunos obstáculos comunes.
Como recordarán la última vez, para introducir la I.A. en su negocio no se necesita un científico espacial.
El primer paso es identificar un caso de negocio.
Tal vez tenga una tarea repetitiva y que consume mucho tiempo. Una prueba de buen olfato para determinar si se considera la posibilidad de resolver un problema de aprendizaje automático.
Pregúntate a ti mismo:-
¿Tengo un cuello de botella en el flujo de trabajo?
¿Tengo un proceso de control de calidad que pueda ser automatizado?
¿Qué tarea(s) manual(es) tiene(n) el mayor costo para la organización?
Si aumento la producción en 10X, ¿qué ruedas esperarías que se caigan primero?
(asumiendo que asignar más personal / reclutamiento, etc. no es una opción)
Los cuellos de botella, el ahorro de costes y los desafíos de expansión son aspectos obvios para empezar a implementar los algoritmos de aprendizaje automático (ML).
Sin embargo, un uso que se pasa por alto de la IA es la garantía de calidad. Los IDH son muy subjetivos cuando se trata de evaluación cuantitativa. Somos intrínsecamente subjetivos y aplicamos nuestros prejuicios y preferencias individuales a nuestro juicio.
Como recordarán de mi anterior post, he esbozado tres ejemplos donde el aprendizaje automático puede ser aplicado para resolver algunos problemas bastante triviales como:-
Clasificación de texto – distinguir automáticamente entre fútbol (USA) y fútbol (Internacional).
Medición de la relevancia entre el texto vinculado en un párrafo y la página de destino.
Aumento de la escala de la generación de contenidos mediante modelos de lenguaje profundo
Habiendo pasado las dos últimas décadas trabajando en SEO, es un buen lugar con algunos ejemplos de aplicaciones de aprendizaje automático. Será un contexto familiar para los lectores familiarizados con el despliegue de SEO a gran escala, a la vez que presentará conceptos que le ayudarán a comprender los fundamentos del ML, independientemente de los conocimientos técnicos o estadísticos. Pero es fuera de la función de adquisición y comercialización que quiero centrarme en este puesto. Por ahora, es el proceso y el enfoque para tratar los problemas de ML lo que quería ayudar a establecer en su mente.
“Por qué” en lugar de “cómo’
Mantenerme centrado en el “Por qué” en vez de en el “Cómo” es posiblemente la lección más valiosa que aprendí en los últimos seis años mientras exploraba el aprendizaje de las máquinas.
Con el aprendizaje de la máquina y la IA en general, es más importante que nunca mantener el enfoque en el problema, de lo contrario hay una tendencia a perderse rápidamente durante semanas o incluso meses.
El campo es vasto y crece tan rápido que cuando parpadees, habrá una nueva metodología para resolver el problema con mayor precisión. Del mismo modo, si se aborda el ML con el deseo de mantener un enfoque práctico, es probable que se sienta abrumado por las matemáticas sin establecer primero una razón sólida de “por qué”.
Image copyright: www.mathworks.com
Afortunadamente, el campo está bien establecido con bibliotecas de software fáciles de usar y altamente optimizadas disponibles para su rápida implementación. Así que no hay necesidad de reinventar la rueda. Por esta razón es importante:-
Comprender el tipo de problema de ML
Familiarizarse con los datos
Enfoque en los objetivos comerciales
Entrenar, probar, medir, iterar
Falla rápido / aprende rápido
Ejemplos de procesos comerciales solucionables por máquina
Predecir los valores de los jugadores de toda la vida
Detección de problemas de juego
Recomendación del producto – los jugadores que juegan “x” también juegan “y
SEO técnico – detección de soft 404.
Procesos de SEO externos – garantía de calidad de los enlaces
Por ahora, examinaremos brevemente los desafíos relacionados con la “predicción del valor del tiempo de vida” y desarrollaremos una intuición más profunda en torno a la causa válida de la detección del “problema del juego”.
Comprensión del problema de aprendizaje de la máquina
La clave para resolver cualquier problema es primero entender el problema. Así que probablemente sea un buen momento para introducir algunos conceptos más fundamentales.
Image copyright: www.mathworks.com
En general, hay dos tipos principales de problemas en el aprendizaje de las máquinas: supervisados y no supervisados. Ambos tipos o problemas requieren datos de entrenamiento.
Problemas de aprendizaje de máquinas supervisadas. Nuestros datos están etiquetados. Para proporcionarnos conjuntos de ejemplos. En los primeros algoritmos de detección de spam, estos serían correos etiquetados como “Spam” y correos etiquetados como ” Ham”.
Problemas de aprendizaje de máquinas sin supervisión. Nuestros datos no están etiquetados o no están clasificados. En cuyo caso usamos algoritmos de aprendizaje automático para ayudar a organizar los datos. Considere una tabla de registros de usuarios, podemos estar buscando algún tipo de similitud o incluso disimilitud, o comportamientos comunes. En los datos de series temporales, como los análisis de la web, podemos estar buscando tendencias o cambios en las tendencias.
Hay literalmente un número ilimitado de aplicaciones para ambos tipos de aprendizaje por máquina. Todo depende de la naturaleza de los datos y de la señal que se quiera extraer del ruido.
Witchcraft está fuera de alcance
Aunque probablemente hayan escuchado mucho sobre el aprendizaje profundo y las redes neuronales, nos mantendremos alejados de este enfoque por ahora. No se preocupe, llegaremos al aprendizaje profundo en futuras publicaciones. Mientras que las redes neuronales profundas a menudo proporcionan mejores resultados y aprendizaje de la máquina estadística, a menudo son difíciles de entrenar, requieren conjuntos de datos significativamente más grandes, y los resultados no pueden ser fácilmente interpretados, convirtiendo la inferencia del modelo en una caja negra.
Las cajas negras no interpretables son geniales si eres un monopolio del motor de búsqueda en un caso antimonopolio de 2.4B bajo escrutinio, pero no tan buenas si estás depurando un clasificador de “problemas de juego”. Para nuestro propósito estamos apuntando a resolver el problema rápidamente, establecer una línea de base para la precisión.
Literalmente funcionan por arte de magia, eso es todo lo que necesitamos saber por ahora. 😉
Familias de algoritmos de aprendizaje automático
Aunque algunos de estos algoritmos suenan como si fueran de la nave estelar Enterprise, la mayoría de las bibliotecas de aprendizaje de máquinas son muy fáciles de usar, implementan el entrenamiento de modelos y la validación (prueba) en dos o tres líneas de código. Ciencia de cohetes, no lo es..
Image copyright: www.mathworks.com
Las tres familias básicas de algoritmos son las siguientes:-
Regresión: calcula la relación probabilística entre las variables con fines de previsión o predicción. Los problemas de regresión son problemas en los que intentamos hacer una predicción a escala continua. Algoritmos: Regresión Lineal, Regresión Bayesiana, Regresión del Vector de Soporte (SVR), Regresión Polinómica, Regresión de la Cresta
Clasificación: calcular la categoría (o clase) de un elemento y la confianza (probabilidad) de la clasificación. Un problema de clasificación es un problema en el que usamos datos para predecir en qué categoría cae algo. Algoritmos: Regresión logística, Clasificador Bayes ingenuo, Máquinas Vectoriales de Apoyo (SVM), Árboles de Decisión, Bosque al azar
Agrupación: agrupar los datos en diferentes clases donde los datos de cada clase comparten la similitud. Un problema de agrupación no está supervisado, no tenemos etiquetas en los datos, por lo que estamos tratando de utilizar los datos para inferir las etiquetas en base a cómo los puntos de datos caen en grupos, clusters o clases. Algoritmos: K-Means, K-Vecinos más cercanos, Cambio medio, Agrupación jerárquica, DBSCAN
Derribando el Problema
Ahora tenemos algunos conceptos básicos fundamentales. Veamos una vez más los siguientes problemas y entendámoslos mejor en términos de problemas de aprendizaje de la máquina:
Problema #1: Predecir los valores de los jugadores de toda la vida (LTV)
Dado que estamos prediciendo el valor del jugador, es decir, un número en una escala continua (por ejemplo, 2.330 dólares) en lugar de una clase discreta (por ejemplo, cat / dog, spam / ham), entonces el problema debería considerarse en general como un “problema de regresión” siempre que tengamos suficientes datos para derivar un modelo preciso. Si no se dispone de datos para predecir con precisión la VLP, un enfoque alternativo sería tomar los datos históricos y replantearse el problema como un problema de clasificación, en el que estamos prediciendo clases, grandes o no.
El personal de adquisición que lea este post ya habrá identificado el problema del “huevo y la gallina”, también conocido por los ingenieros de la ML como el problema del “arranque en frío”. En otras palabras, los nuevos jugadores no tienen un historial de juego. Esto nos lleva a resolver un nuevo problema, lo que podemos aprender de los datos de registro, si el jugador se ha conectado a Facebook o Twitter, lo que podemos aprender de su código postal, tipo de navegador, tipo de dispositivo, operador de red y análisis avanzado de usuarios de Google.
En este punto, el problema se extiende al enriquecimiento de datos, la recuperación de información, la desambiguación de los nombres de las personas * e incluso un problema de inteligencia de código abierto (OSINT) **.
* La desambiguación del nombre de la persona es típicamente vista como un asunto de agrupación no supervisado, donde el objetivo es dividir los contextos de un nombre en diferentes grupos, cada uno representando a una persona del mundo real. (Con una cuenta de Facebook y un código postal, puedes identificar con precisión el perfil de LinkedIn?)
** La Inteligencia de Código Abierto (OSINT) es una metodología multi-método (cualitativo, cuantitativo) para recolectar, analizar y tomar decisiones sobre datos disponibles públicamente para ser usados en un contexto de inteligencia. (También conocido como espionaje digital)
¡Por favor, no me juzgues todavía! Consideremos ahora el caso de los negocios.
Nota: No pensaba cubrir la OSINT y la Desambiguación de Nombres de Personas en esta serie, pero si quieres que cubra estos temas en el futuro, envía un tweet a @igamingsummit y diles que es de tu interés.
Motivación y caso de negocio
La medida más fundamental de la VLP sería un “todo en uno” utilizando promedios históricos basados en jugadores anteriores, idealmente segmentados por país.
Este “todo” proporcionas:-
El equipo de retención: una valiosa visión y un sólido KPI.
El equipo de afiliados: comercialización de municiones.
Sin embargo, con un poco de minería de datos / enriquecimiento y un poco de inferencia de modelos. Somos capaces de ayudar tanto a la conversión como a la reactivación.
Activación:- Ya que muchos casinos en línea resuelven el problema de activación por fuerza bruta, es decir, utilizando centros de llamadas dedicados, bien entrenados, bien dotados de personal y multilingües. Considere el beneficio empresarial de poder dirigir a los potenciales apostadores al recurso de centro de llamadas de mejor rendimiento. Incluso los operadores más pequeños y con menos recursos podrían dar prioridad incluso a los recursos limitados para ayudar al jugador en el primer paso del depósito.
Retención:- De manera similar, retener o reactivar a los jugadores es tanto una ciencia como una forma de arte. La capacidad de determinar con precisión la distribución 80/20 en una base de datos de jugadores caducados, junto con estrategias de reactivación óptimas. Ahora tenemos una poderosa motivación para el equipo de retención.
Recuerden: el objetivo es identificar oportunidades para automatizar o semi-automizar y luego optimizarlas gradualmente.
Ahora que estamos empezando a pensar en problemas específicos que en términos de los datos disponibles, el caso de negocio y el tipo de salida, veamos otro ejemplo.
Problema #2: Detección de problemas de juego
Dado que vengo de un entorno de marketing digital (Search), es justo decir que las cuestiones regulatorias y éticas relacionadas con iGaming son generalmente lo último que tengo en mente. Sin embargo, ayer mismo estuve hablando con un amigo que me preguntó sobre el aprendizaje de las máquinas y la detección de “Problem Gambling”, llamándome la atención sobre algunas de las soluciones de inteligencia artificial que actualmente son pioneras en este espacio.
Es un problema interesante, y aunque nunca antes había considerado el problema. pensé que sería apropiado incluir algunas ideas sobre cómo abordaría este digno desafío.
Éticamente, es un tema importante, especialmente dada la situación actual de COVID y tal vez poner mis pensamientos iniciales puede estimular la discusión y la exploración del problema y destacar algunos de los desafíos que esperaría con un modelo de aprendizaje de la máquina.
¿Qué vino primero, el pollo o el huevo?
IEn el ejemplo anterior señalamos el problema del “arranque en frío”, también conocido como el problema del “huevo y la gallina”. El problema del “arranque en frío” generalmente se refiere a problemas de agrupamiento no supervisados. Un ejemplo es el de los motores de recomendación (filtrado en colaboración).
Para inferir agrupaciones de comportamiento similar, primero se requiere algún comportamiento del usuario del que se pueda inferir similitud en el sabor, atribuyendo el usuario a una agrupación determinada. (Traducción al inglés, Netflix no puede recomendar una película hasta que haya visto y calificado al menos una película. Cuantas más películas veas y califiques, mejores serán las recomendaciones).
Desde el punto de vista de los datos, hay dos tipos de problemas de juego.
1. Un jugador recreativo que desarrolla un problema con el tiempo mientras juega en su casino.
2. un nuevo jugador que se acaba de registrar y ya tiene un problema de juego.
Tengan en cuenta que tenemos desafíos tanto de negocios como de ética.
En el caso del jugador que desarrolla el problema con el tiempo…
¿Hay algún evento en la línea de tiempo de los datos que haya desencadenado el problema de juego (como una victoria del premio gordo)? En cuyo caso, ¿en qué momento el negocio estaría contento de cerrar la cuenta, mientras el jugador está perdiendo las ganancias de vuelta a la casa? ¿Existe un medio feliz? ¿Cómo sopesamos a los profesionales de los negocios?
El algoritmo no debe disparar falsos positivos, ya que los jugadores problemáticos se ven casi exactamente igual que los grandes apostadores y no hay premios por bloquear la cuenta de un nuevo gran apostador.
Antes de seguir adelante, ahora es tan buen momento como cualquier otro para considerar cómo medimos la precisión en los sistemas de aprendizaje de las máquinas.
Precisión de la predicción, precisión vs. recuerdo
Como vemos en nuestro ejemplo del “problema del juego”, la precisión es crucial, los falsos positivos son totalmente inaceptables. Como tal, cuando medimos la precisión en el aprendizaje de la máquina, medimos tanto la precisión como la memoria.
Los orígenes de la precisión y la memoria como medida de la exactitud provienen del campo de la recuperación de información y de los motores de búsqueda como medio para evaluar la calidad de un conjunto de documentos recuperados o de resultados de búsqueda.
La precisión es la proporción de resultados relevantes en la lista de todos los resultados de búsqueda devueltos. La recuperación es la proporción de los resultados pertinentes devueltos por el motor de búsqueda con respecto al número total de resultados pertinentes que podrían haber sido devueltos.
Prometo que no habrá más matemáticas en este post.
Recapitulando lo que hemos aprendido
Entendemos por qué la precisión es crucial. Los falsos positivos son inaceptables.
Hemos identificado dos tipos distintos de “jugador problemático” desde el punto de vista de los datos. 1) nuevos jugadores depositantes que tienen un problema de juego preexistente. 2) jugadores existentes que desarrollan un problema de juego durante su vida de jugador.
Ambos tipos son problemas claramente diferentes que requieren diferentes enfoques
Entendemos que el problema del “arranque en frío” se aplica a los algoritmos de agrupación no supervisados.
Con esto en mente, continuemos explorando el “problema de Gambling” un poco más profundo.
Ya que estamos abordando el problema usando el aprendizaje de la máquina estadística en lugar de un aprendizaje profundo, el conocimiento específico del dominio es importante. Como mencioné que el aprendizaje profundo funciona por arte de magia, explicaré por qué en un post posterior, pero por ahora, sólo confía en mí.
Al acercarse a un problema de aprendizaje de la máquina estadística, la experiencia en el dominio es vital. La comprensión del dominio del problema nos proporciona la intuición de qué datos son importantes para nuestro(s) modelo(s) y como no tengo experiencia en este lado del negocio.
Pedí consejo a mi amigo, Yara de Pearl Trust se especializa en licencias de juego en Curaçao, habiéndome hecho primero consciente del asunto del “problema de juego” y la necesidad del negocio de un enfoque de IA. Pensé que quién mejor para pedirle a Yara una visión adicional:-
Veamos algunos datos adicionales que ella amablemente me proporcionó.
Actualmente, los “jugadores problemáticos” se encuentran principalmente bajo la competencia del servicio de atención al cliente, el oficial de RSE (responsabilidad social corporativa) o el oficial de juego responsable designado con la asistencia del T.I. para suministrar datos específicos a las partes interesadas.
Actualmente el proceso es ampliamente manual con la ayuda de la I.T. Sin embargo, hay algunas empresas que están desarrollando soluciones automatizadas para este problema.
Los indicios más comunes de “problemas de juego” incluyen:-
Persiguiendo pérdidas
Tiempos de juego erráticos
Extensión de la duración de las sesiones
El proceso actual:-
Los jugadores potenciales se añaden a la lista de vigilancia
Si el problema persiste y/o se deteriora se recomienda la autoexclusión
Si se ignora la recomendación de autoexcluirse, el bloqueo de la cuenta se hace como último recurso
Así que ahora que entendemos mejor el proceso interno para tratar los “problemas de juego”, tenemos objetivos comerciales en los que podemos centrarnos.
Objetivos de los problemas de Gambling
Objetivo #1: Automatizar la generación de la lista de vigilancia para ser distribuida a las partes interesadas.
Objetivo #2: Generar datos resumidos suplementarios para incluirlos en un informe.
Continuaremos explorando este fascinante problema con más detalle en el próximo post. Exploraremos algunos de los algoritmos y sus características en relación con los datos con los que típicamente trabajaríamos. A medida que exploremos estos y otros problemas empezaremos a desarrollar la intuición en torno a los distintos tipos de problemas.
Si tienes algún comentario, consideración, pregunta o tema específico que quieras que responda/cubra en futuras publicaciones, por favor, envía un tweet a @igamingsummit.
Acerca de la exposición virtual de SiGMA Europa:
El Grupo SiGMA se complace en anunciar el lanzamiento de su evento de noviembre, SiGMA Europe Virtual Expo. El evento en línea, que se llevará a cabo del 24 al 25, se centrará en el mercado europeo de juegos y tecnología.
Para más información sobre cómo patrocinar este evento, por favor, ponte en contacto con Hamza y para explorar las oportunidades de hablar, ponte en contacto con Jeremy. Para inscribirse en la exposición, haz clic aquí.










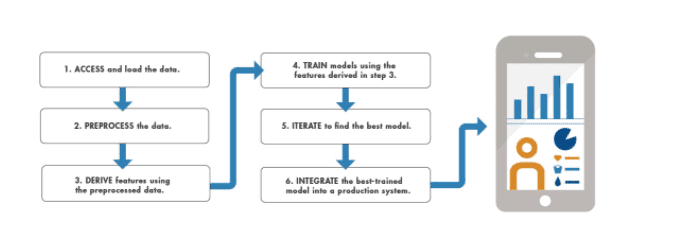
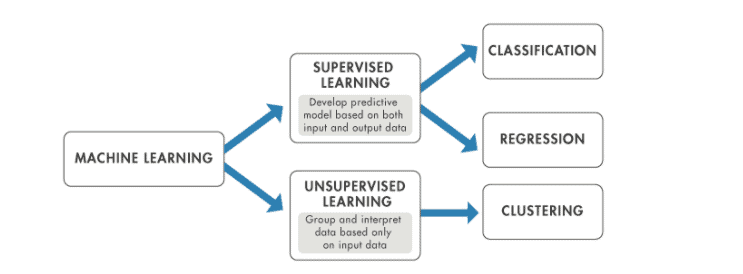
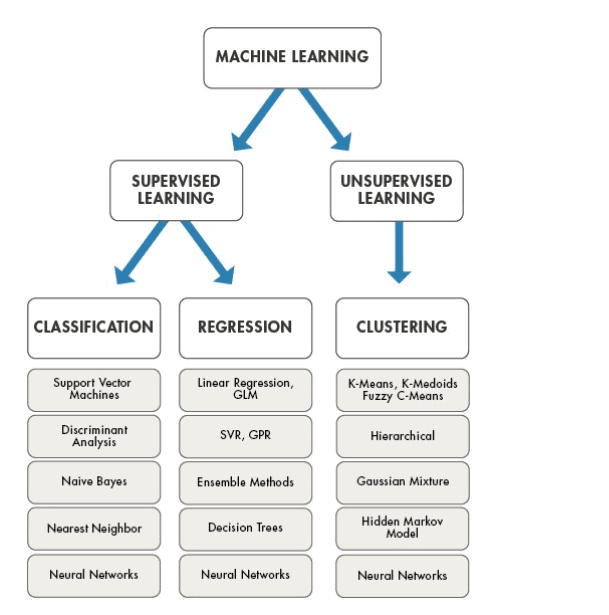 Image copyright: www.mathworks.com
Image copyright: www.mathworks.com 









