Machine Learning: General approach to casino business cases
Machine Learning by Paul Reilly, AI engineer, founder of flashbitch.com, a largely AI-generated casino bonus website, a technology enthusiast and speaker.
Following an SEO career which spanned two decades, Paul turned his attention to the practical uses of artificial intelligence, leading him to regularly drop in on the university AI research team while exploring new ways to make a splash as a casino affiliate.
In the previous post we looked at the motivation for exploring A.I.. Now let’s look into some practical examples of real world problems which you may be familiar with, we’ll examine the type of problem and explore approaches for solving them as well as some common pitfalls.
As you may recall from last time, introducing AI to your business doesn’t require a rocket scientist.
The first step is to identify a business case.
Perhaps you have a repetitious, time consuming task. A good smell test to determine whether to consider solving a problem with machine learning.
Ask yourself:-
Do I have a workflow bottleneck?
Do I have a quality control process which can be automated?
Which manual task(s) carry the greatest cost to the organisation?
If I increase output by 10x, which wheels would you expect to fall off first? (assuming allocating more staff / recruiting etc isn’t an option)
Bottlenecks, cost savings and scaling challenges are obvious places to start looking at implementing machine learning (ML) algorithms.
However one overlooked use for AI is quality assurance. HumanDs are very subjective when it comes to quantitative assessment. We’re inherently subjective and apply our individual biases and preferences to our judgement.
As you may recall from my previous post I outlined three examples where machine learning can be applied to solve some quite trivial problems such as:-
Text classification – automatically distinguish between football (USA) and football (International).
Measuring relevance between linked text in a paragraph and the target page.
Scaling content generation using deep language models
Having spent the last two decades working on SEO, It’s as good a place with some example applications for machine learning. It will be a familiar context to readers familiar with deploying SEO at scale, while introducing concepts to help you understand the basics of ML, regardless of technical or statistical know-how. But it is outside of the acquisition and marketing function that I want to focus on in this post. For now, it’s the process and approach to tackling ML problems that I wanted to help establish in your mind.
‘Why’ rather than ‘How’
Staying focussed on ‘Why’ rather than ‘How’ is possibly the most valuable lesson I learned throughout the last six years as I explored machine learning.
With machine learning and AI in general it’s more important than ever to stay focussed on the problem otherwise there is a tendency to quickly wander off into exploratory rabbit holes, for weeks or even months at a time.
The field is vast and growing so quickly that by the time you come back up for air there will be a new methodology to solve the problem more accurately. Similarly, if you approach ML with a desire to maintain a hands-on approach, you’re likely to be overwhelmed by the mathematics without first establishing a solid reason ‘Why’.
Image copyright: www.mathworks.com
Fortunately, the field is well established with easy to use, highly optimised software libraries available to quickly implement. So no need to reinvent the wheel. For this reason it’s important to:-
Understand the type of ML problem
Familiarise yourself with the data
Focus on the business objectives
Train, test, measure, iterate
Fail fast / learn fast
Examples of machine solvable business processes
Predicting life-time player values
Problem gambling detection
Product recommendation – players who play ‘x’ also play ‘y’
Technical SEO – soft 404 detection.
Offsite SEO processes – link quality assurance
For now, we’re going to briefly look at the challenges related to ‘predicting life-time value’ and develop some deeper intuition around the worthy cause of ‘problem gambling’ detection.
Understanding Machine Learning Problem
The key to solving any problem is first understanding the problem. So it’s probably a good time to introduce some more foundational concepts.
Image copyright: www.mathworks.com
Generally speaking there are two main types of problems in machines learning: supervised and unsupervised. Both types or problems require training data.
Supervised machine learning problems. Our data is labelled. So as to provide us with sets of examples. In early email spam detection algorithms these would be emails labelled ‘spam’ and emails labelled ‘ham’.
Unsupervised machine learning problems. Out data is unlabelled or uncategorised. In which case we use machine learning algorithms to help organise the data. Consider a table of user records, we may be looking for some kind of similarity or even dissimilarity, or common behaviours. In time series data, such as web-analytics we may be looking for trends or changes in trends.
There are literally an unlimited number of applications for both types of machine learning. It all depends on the nature of your data and the signal you want to extract from the noise.
Witchcraft Is Out Of Scope
While you’ve probably heard a lot about deep learning and neural networks, we’re going to stay away from this approach for now. Don’t worry, we’ll come to deep learning in future posts. While deep neural networks often provide better results and statistical machine learning, they’re often difficult to train, they require significantly larger data sets, and the results cannot be easily interpreted, turning the model inference into a black box.
Uninterpretable black boxes are great if you’re a search engine monopoly in a €2.4B antitrust case under scrutiny, but not so good if you’re debugging a ’problem gambling’ classifier. For our purpose we’re aiming to solve the problem quickly, establish a baseline for accuracy.
They literally work by magic, that’s all we need to know for now. 😉
Machine Learning Families of Algorithms
While some of these algorithms sound like they’re from the Starship Enterprise, most machine learning libraries are very easy to use, they implement model training and validation (testing) in two or three lines of code. Rocket science, it is not.
Image copyright: www.mathworks.com
The three basic families of algorithms are as follows:-
Regression: compute the probabilistic relationship between variables for the purposes of forecasting or prediction. Regression problems are problems where we try to make a prediction on a continuous scale. Algorithms: Linear Regression, Bayesian Regression, Support Vector Regression (SVR), Polynomial Regression, Ridge Regression
Classification: compute the category (or class) of an item and the confidence (probability) of the classification. A classification problem is a problem where we are using data to predict which category something falls into. Algorithms: Logistic Regression, Naive Bayes Classifier, Support Vector Machines (SVM), Decision Trees, Random Forest
Clustering: group data into different classes where data in each class share the similarity. A clustering problem is unsupervised, we don’t have labels in the data, so we are trying to use data to infer the labels based on how the data points fall into groups, clusters or classes. Algorithms: K-Means, K-Nearest Neighbours, Mean-shift, Hierarchical clustering, DBSCAN
Breaking Down The Problem
Now we have some basic foundational concepts. Let’s look once again at the following problems and better understand them in terms of machine learning problems:-
Problem #1: Predicting life-time player values (LTV)
Since we’re predicting the player’s value, ie. a number on a continuous scale (example: €2,330) as opposed to a discrete class (example: cat / dog, spam / ham), then the problem should generally be considered a ‘regression problem’ providing we have sufficient data from which to derive an accurate model. Should the data not be available to accurately predict LTV, an alternative approach would be to take the historical data, and rethink the problem as a classification problem, where we’re predicting classes, high-roller or not.
The acquisition people reading this post will have already spotted the ‘chicken and egg’ problem, also known to ML engineers as the “cold start” problem. Namely new players don’t have a playing history. This leads us to solving a new problem, what can we learn from the registration data, did the player connect with facebook or twitter, what can we learn from their postcode, browser type, device type, network carrier and google’s advanced user analytics.
At this point, the problem fans out into data enrichment, information retrieval, person-name disambiguation* and even an open source intelligence (OSINT)** problem.
* Person Name Disambiguation is typically viewed as an unsupervised clustering problem where the aim is to partition a name’s contexts into different clusters, each representing a real world people. (In plain English… given a facebook account and a postcode, can you accurately identify their LinkedIn profile?)
** Open-source intelligence (OSINT) is a multi-methods (qualitative, quantitative) methodology for collecting, analysing and making decisions about data accessible in publicly available sources to be used in an intelligence context. (AKA digital spying)
Please don’t judge me just yet! Let’s now consider the business case.
Note: I wasn’t planning on covering OSINT and Person Name Disambiguation in this series but if you would like me to cover these topics in the future please tweet @igamingsummit and let them know it’s of interest.
Motivation & Business Case
The most fundamental measurement of LTV would be an all-in-one ‘catch-all’ using historical averages based on past players, ideally segmented by country.
This ‘catch-all’ provides:-
the retention team: valuable insight and a solid KPI.
the affiliate team: marketing ammunition.
However, with some data mining / enrichment and a little model inference. We’re able to assist both conversion and reactivation.
Activation:- Since many online casinos solve the activation problem by brute force, ie. using dedicated, well trained, well staffed, multilingual call centres. Consider the business benefit of being able to route the potential high-rollers to the best performing call centre resource. Even smaller, less well resourced operators would be able to prioritise even limited resources to assist the player through the first deposit step.
Retention:- Similarly, retaining or reactivating players is both a science and an art form. The ability to accurately determine the 80/20 distribution across a database of lapsed players, along with optimal reactivation strategies. Now we have a powerful motivation for the retention team.
Remember: the goal is to identify opportunities to automate or semi-automate then incrementally optimise.
Now that we’re starting to think about specific problems which in terms of the available data, the business case and the type of output, let’s look at another example.
Problem #2: Problem Gambling Detection
Since I come from a digital marketing (Search) background, it’s fair to say that regulatory and ethical issues related to iGaming are generally the last thing on my mind. However I was speaking with a friend just yesterday, who asked me about machine learning and ‘Problem Gambling’ detection, drawing my attention to some of the artificial intelligence solutions which are currently pioneering this space.
It’s an interesting problem, and while I’d never previously considered the problem. I thought it would be fitting to include some thoughts on how I’d approach this worthy challenge.
Ethically, it’s an important topic especially given the current COVID situation and perhaps putting out my initial thoughts may spur on discussion and further exploration of the problem and highlight some of the challenges I’d expect with a machine learning model.
Which Came First, The Chicken Or The Egg?
In the previous example we noted the “cold start” problem AKA the “chicken and egg” problem. The “cold start” problem generally refers to unsupervised, clustering problems. One example being, Recommendation Engines (Collaborative Filtering).
In order to infer clusters of similar behaviour we first require some user behaviour from which to infer similarity in taste, by attributing the user to a given cluster. (English translation, Netflix cannot recommend a movie until you’ve watched and rated at least one movie. The more movies you watch and rate, the better the recommendations.)
From a data standpoint are two types of problem gambler.
1. a recreational player who develops a problem over time while playing at your casino.
2. a new player who has just registered and already has a gambling problem.
Note we have both business and ethics challenges.
In the case of the player who develops the problem over time…
Is there an event on the timeline in the data which triggered the gambling problem (such as a jackpot win)? In which case, at what point would the business be happy locking the account, while the player is losing the winnings back to the house? Is there a happy medium? How do we weigh business priorities?
The algorithm must not trigger false positives, since problem gamblers look almost exactly like high rollers and there are no prizes for locking the account of a new high roller.
Before we go any further, now is as good a time as any to consider how we measure accuracy in machine learning systems.
Prediction Accuracy, Precision vs Recall
As we see from our ‘gambling problem’ example accuracy is crucial, false positives are entirely unacceptable. As such, when we measure accuracy in machine learning, we measure both precision and recall.
The origins of precision and recall as a measurement of accuracy come from the field of information retrieval and search engines as a means to evaluate the quality of a set of retrieved documents or search results.
The precision is the proportion of relevant results in the list of all returned search results. The recall is the ratio of the relevant results returned by the search engine to the total number of the relevant results that could have been returned.
We understand why precision is crucial. False positives are unacceptable.
We’ve identified two distinct types of ‘problem gambler’ from a data standpoint. 1) new depositing players who have a preexisting gambling problem. 2) existing players who develop a gambling problem during their player lifetime.
Both types are distinctly different problems requiring different approaches
We’re understand the “cold-start” problem applies to unsupervised, clustering algorithms.
With this in mind let’s continue to explore ‘problem gambling’ a little deeper.
Since we’re approaching the problem using statistical machine learning as opposed to deep learning, domain specific knowledge is important. As I mentioned deep learning works by magic, I’ll explain why in a later post, but for now, just trust me.
As you approach a statistical machine learning problem, domain expertise is vital. An understanding of the problem domain provides us with the intuition of which data is important to our model(s) and since I have no experience in this side of the business.
I called on my friend for advice, Yara from Pearl Trust specialises in Gaming licenses in Curacao, having first made me aware of the ‘problem gambling’ matter and the business need for an AI approach. I figured who better to ask than Yara for additional insight:-
Let’s look at some additional insight she kindly provided.
Currently ‘problem gamblers’ mostly fall under the remit of customer service, CSR (corporate social responsibility) officer or designated Responsible Gambling Officer with assistance from the I.T. to supply specific data to stakeholders.
Currently the process is widely manual with assistance from IT. However there are a few companies now developing automated solutions to this problem.
Common indication of ‘problem gambling’ include:-
Chasing losses
Erratic playing times
Extended session lengths
The current process:-
Potential players added to watch list
If the problem persists and/or deteriorates self-exclusion is recommended
If recommendation to self-exclude is ignored, account lock is made as a final resort
So now that we better understand the internal process for dealing with ‘problem gambling’, we have business objectives we can focus on.
Problem Gambling Objectives
Objective #1: automate the generation of the watchlist to be distributed to stakeholders.
Objective #2: generate supplemental summary data to include in a report.
We will continue exploring this fascinating problem in further detail in the next post. We’ll explore some of the algorithms and their characteristics in relation to the data we’d typically be working with. As we explore these and other problems we will start to develop intuition around the distinctly different types of problems.
If you do have any specific thoughts, considerations, questions, topics you’d like me to answer/cover in future posts, please tweet @igamingsummit.
About SiGMA Europe Virtual Expo:
SiGMA Group is excited to announce the launch of their November event, SiGMA Europe Virtual Expo. The online event, which runs from the 24th to 25th, will focus on the European gaming and tech marketplace.
For more information about how to sponsor this event please contact Hamza and to explore speaking opportunities get in touch with Jeremy. To register for the expo click here.










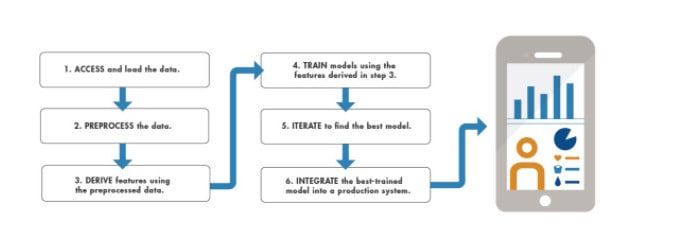
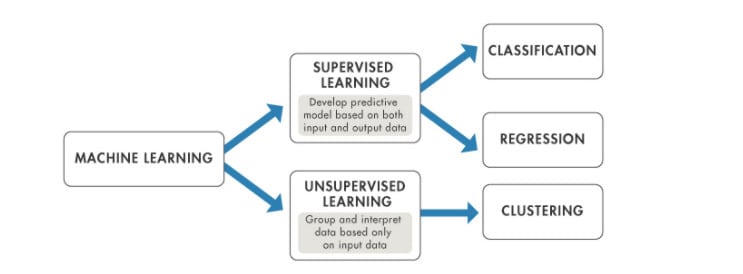
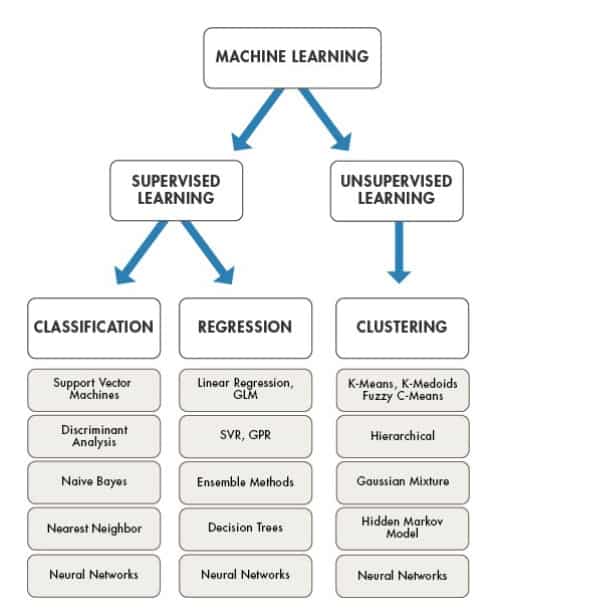 Image copyright: www.mathworks.com
Image copyright: www.mathworks.com 













